背景
在现在的业务系统中都避免不了和数据库打交道,提到数据库那就避免不了主键的问题。
- 在单机场景下,很简单,就是数据库中某张表写入数据,这种场景最好的方法就是直接使用
MySQL的自增ID,也不用担心主键冲突,性能也好。 - 在分布式场景则会有以下问题:
- 如果依赖数据库自增ID,性能会有很大问题
- 如果如果使用
UUID,虽然能够避免主键冲突的问题,但是UUID是无序的,在查询时性能也会有问题,且可读性不高
因此,便需要一种分布式ID生成的方法,他需要保证有序,并且分布式不会冲突
雪花算法
雪花算法的由来就不赘述了,(WIKI有很多)
原理
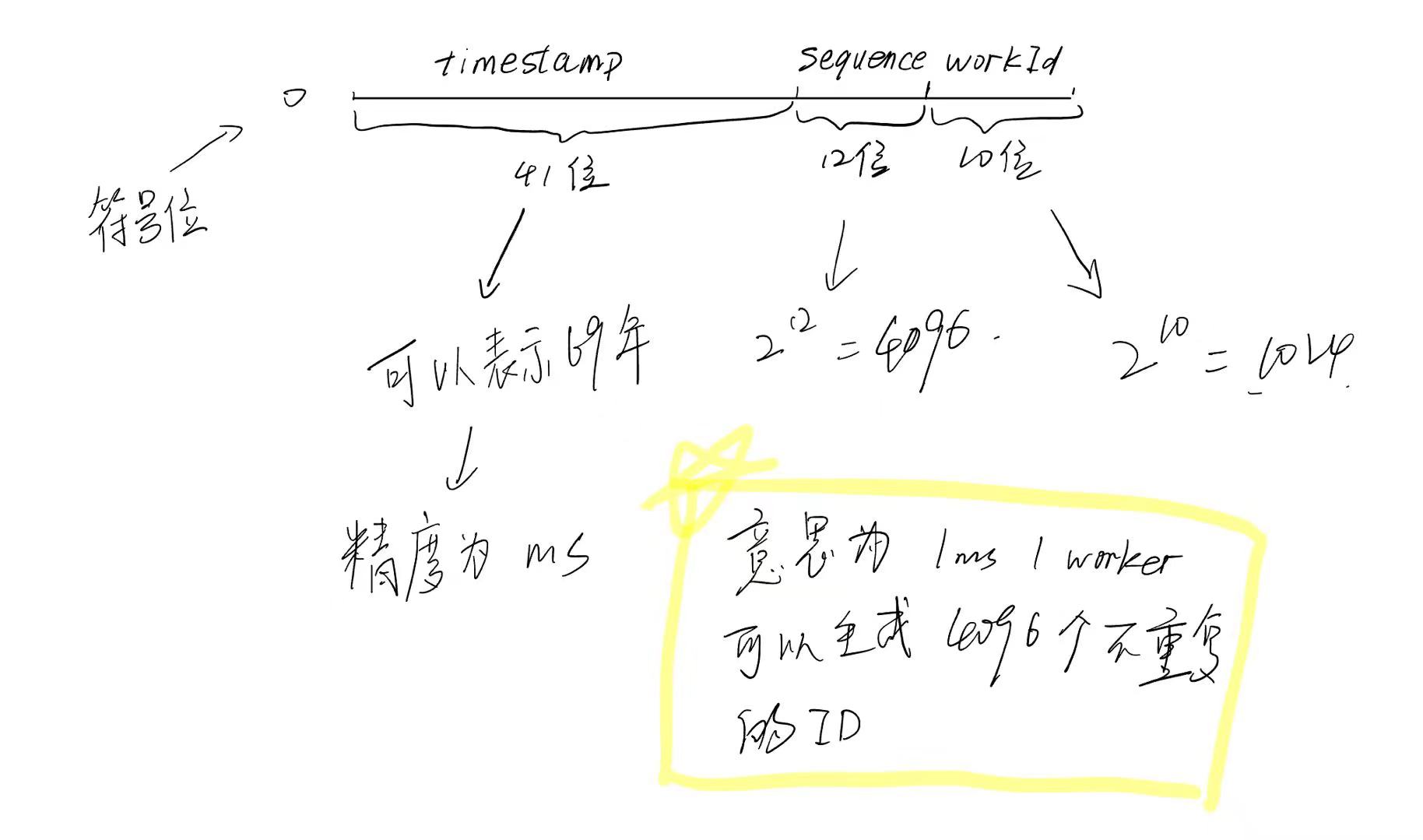
一个雪花算法生成的ID为64位,算法将这64位分为多个块,每一块有不同的含义:
- 1位是符号位,也就是最高位,始终是0,没有任何意义,因为要是唯一计算机二进制补码中就是负数,0才是正数。
- 41位是时间戳,具体到毫秒,41位的二进制可以使用69年,因为时间理论上永恒递增,所以根据这个排序是可以的。
- 10位是机器标识,可以全部用作机器ID,也可以用来标识机房ID + 机器ID,10位最多可以表示1024台机器。
- 12位是计数序列号,也就是同一台机器上同一时间,理论上还可以同时生成不同的ID,12位的序列号能够区分出4096个ID。
如图
Golang实现
实现1
- 初始化一个
Generator - 如果没有输入机器ID自动生成一个机器ID
- 提供原子的
NextID方法 NextID首先获取当前时间戳进行比较,向左移41位,添加WorkerID,ID原子自增最后拼接起来
结构:
const (
timestampBits = uint(41)
sequenceBits = uint64(12)
workerBits = uint64(9)
timestampShift = sequenceBits + workerBits
sequenceMask = -1 ^ (-1 << sequenceBits)
timestampMax = -1 ^ (-1 << timestampBits)
)
type Snowflake1 struct {
sync.Mutex
timestamp int64
sequence int64
workerId int64
}
NextID实现:
func (s *Snowflake1) NextID() int64 {
// 并发安全
s.Lock()
// 获取当前时间错
now := getNowTime()
// 如果和当前时间戳一样,那么代表这一毫秒生成了多个ID,需要sequence + 1
if now == s.timestamp {
s.sequence = (s.sequence + 1) & sequenceMask
// ID + 1之后溢出了,这个时候就需要等待下一个时间错
if s.sequence == 0 {
for now <= s.timestamp {
now = getNowTime()
}
}
} else {
// 如果当前时间戳和之前的不一样,直接重新计数
s.sequence = 0
}
// 时间溢出场景,则需要更新下base时间戳
t := now - gUnixTimestamp
if t > timestampMax {
s.Unlock()
fmt.Errorf("t must be less than timestamp max")
return 0
}
s.timestamp = now
// 首先 时间戳左移41位;idCount数左移12位;最后拼接上workerid
r := (t << timestampShift) | (s.sequence << workerBits) | s.workerId
s.Unlock()
return r
}
实现2
在上面这种方式里,每次ID的获取都需要锁,并且频繁调用time.Now()获取当前时间戳,这里可以优化,定时获取时间戳+使用Golang的原子操作:
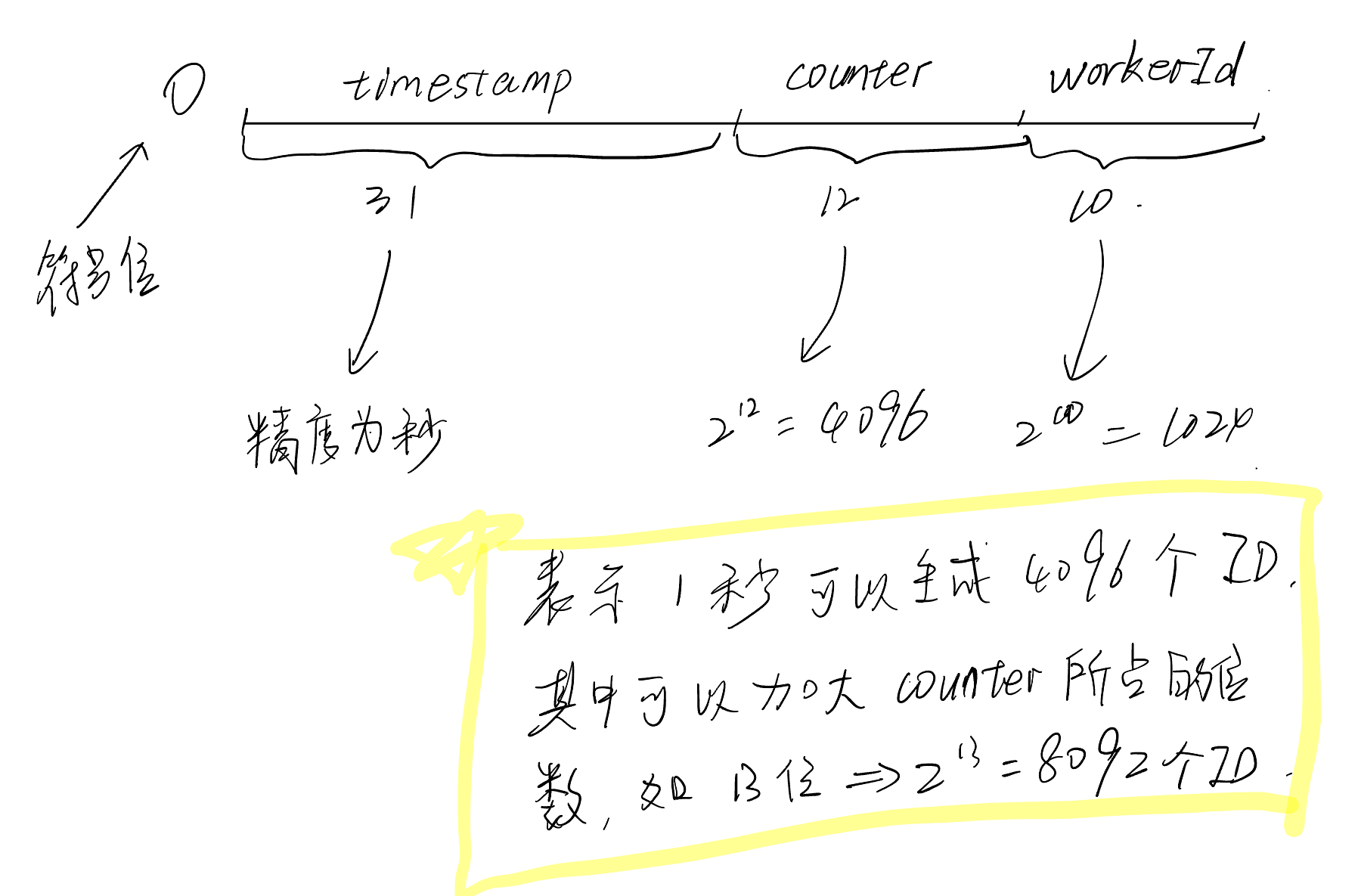
- 初始化一个
Generator - 设置或者生成当前机器ID
Generator提供NextID方法
结构:
type Snowflake2 struct {
sync.Mutex
workerId int64
timestamp int64
}
实现:
func NewSnowflake2(ops ...option2) *Snowflake2 {
sf := &Snowflake2{
workerId: 1,
timestamp: time.Now().Unix() << 32,
}
for _, op := range ops {
op(sf)
}
// 时间戳的更新由一个协程单独完成
go func() {
// 尽量保持整秒
time.Sleep(time.Until(time.Now().Truncate(time.Second).Add(time.Second)))
tk := time.NewTicker(time.Second)
now := time.Now().Unix()
sf.updateTimestamp(now)
for {
now := <-tk.C
sf.updateTimestamp(now.Unix())
}
}()
return sf
}
func (s *Snowflake2) NextID() int64 {
// 使用原子操作来递增Counter
i := atomic.AddInt64(&s.timestamp, 1)
// 高32位为时间戳,中间位Counter,最后为WorkerId
return (i & high32) | ((i & sequenceMask) << sequenceBits) | s.workerId
}
// 并发安全的更新时间戳
func (s *Snowflake2) updateTimestamp(ts int64) {
s.Lock()
ts = ts << 32
if s.timestamp == ts {
for ts <= s.timestamp {
ts = time.Now().Unix() << 32
}
}
s.timestamp = ts
s.Unlock()
}
性能对比
goos: darwin
goarch: arm64
pkg: github.com/Mr-LvGJ/jota/id
Benchmark_Snowflake1 49220192 244.2 ns/op
Benchmark_Snowflake2 1000000000 6.866 ns/op
PASS
ok github.com/Mr-LvGJ/jota/id 20.338s
从中可以看出,第二中实现的性能优化很多
问题
- 时间回拨
时间回拨时会导致之前时间戳的Counter重复生成,因此上面有段逻辑
ts = ts << 32
if s.timestamp == ts {
for ts <= s.timestamp {
ts = time.Now().Unix() << 32
}
}
通过这段逻辑可以避免更新成同一个或者更旧的时间戳